


文章目录[隐藏]
 有了AI,我们在构思当中,可以减少一些在细节上花费的力气。当然,在AI在陈述事情时,还是很容易编造内容,所以如果使用了AI提供的事实内容,为保证真实性,一定要核查。如果是借用其提供的细节描述、修辞、创造的文学内容,则根据需要选择,不一定核查。现在写作或者创造内容,一定要自己的思路,富有经验的思路教给AI,就是好师傅教好学生,可以触类旁通地解决不同的问题,自己的思路提交给AI就相当于AI提示词。
有了AI,我们在构思当中,可以减少一些在细节上花费的力气。当然,在AI在陈述事情时,还是很容易编造内容,所以如果使用了AI提供的事实内容,为保证真实性,一定要核查。如果是借用其提供的细节描述、修辞、创造的文学内容,则根据需要选择,不一定核查。现在写作或者创造内容,一定要自己的思路,富有经验的思路教给AI,就是好师傅教好学生,可以触类旁通地解决不同的问题,自己的思路提交给AI就相当于AI提示词。
服务器问题类型
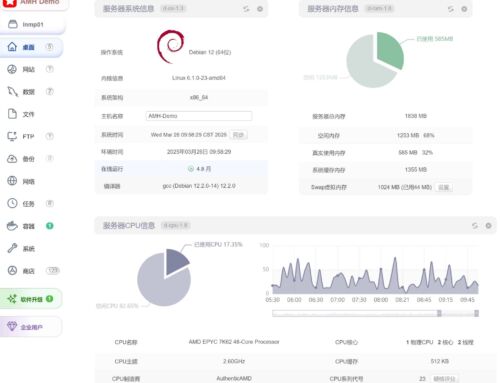
新年后,因为买了新服务器,硬件更好了,我整了一台服务器,之后顺便又整了几台,结果都出现了不同程度的问题。这里的服务器是指不带桌面显示的长时间运行的软硬件综合系统。根据我的经验,服务器一般会有以下几个方面的问题:
- 软件问题(设置、配置文件、个人操作、文件)
- 操作系统问题(权限、内核、运行依赖库、SDK、兼容性)
- 硬件问题(驱动、接口、电源、电子元件、BIOS)
- 网络问题(连通性、路由、光猫、网线、软路由的网络服务)
- Docker和虚拟机问题(使用虚拟化技术时,文件与硬件权限、虚拟网络)
软件问题
从软件的角度来说,例如网页服务Nginx有一个全局配置文件,对于每一个网站也有各自的配置文件。这些配置文件之间存在依赖关系,不能重复也不能错乱。这是我新年搞迁移网站时得到的经验。另外,对于普通人而言,还有一些低级错误,如没有找到合适的文件、文件损坏、没有保存合适的版本、错误地复制内容等,也可能导致软件方面的问题。
操作系统问题
对于操作系统而言,只要不是蓝屏,问题通常比较好办。但是,如果不想重装系统,而又想干净地解决问题,还是需要逐步排查。对于服务器操作系统,权限是常见的问题。软件在不同操作系统上的兼容性也有所不同,尤其是大数据组件,在Windows上运行时大多会遇到权限问题。即使这台服务器只有你一个ROOT用户,服务进程会用不同的用户来运行,因此也需要处理用户权限。此外,虽然Linux服务器有包管理系统能很好地帮我们安装所需的依赖,但有些问题可能是由于内核本身决定的,很难再做改变或修复。例如OpenWrt系统,不能随便安装KMOD模块,也不能像完整的Linux系统那样不断升级内核。
硬件问题
硬件问题的解决如果有冗余的硬件就比较好排查。可以从北桥的几大组件开始,包括CPU、内存、显卡,其中内存坏的可能性较高。笔记本电脑的CPU、显卡、主板通常是集成在一起的,如果排除了系统与软件的问题,就需要找厂家解决。而主板有很多电子元器件,北桥芯片和南桥芯片我没坏过,但如果真到了坏主板的地步,电源也要顺便检查。此时已经很难通过启动主机来判断问题,那就需要使用万用表。
网络问题
在中国,网络连通性始终是一个很大的问题。如果有条件,最好使用自己的代理。如果无法上网,排除了系统和路由的问题后,一般需要找运营商解决光猫、网线、光纤等问题。软路由系统不适合像一般的服务器那样频繁折腾,来回安装软件服务可能会导致家庭断网。如果软路由性能足够,只需要安装满足主要需求的服务即可。如果性能还有余量,可以通过虚拟化技术安装不同的服务,从而避免影响系统的稳定性。
Docker和虚拟机问题
我对虚拟化技术的使用不多,对Docker的研究也只是够用就好。之前出现的一些问题主要围绕文件权限和网络连通性。如果是单个人单节点使用,我则选择用最高权限和HOST网络。
解决的思路
解决服务器问题的思路有很多,这里分享一下自己在实际操作中用到的方法。这些方法并不是孤立的,而是可以结合使用,根据具体情况灵活调整。
第一:日志是关键
找到日志是解决问题的第一步,也是最重要的一步。如果没有现成的日志记录,也要想办法创造日志。例如,可以通过手动增加调试信息、开启更详细的日志等级,或者使用第三方工具来捕获系统或应用程序的行为。
- 日志的作用:日志能够帮助我们了解问题发生的时间、地点以及原因。例如,Nginx 的错误日志可以告诉我们某个请求失败的原因,而系统日志(如
/var/log/syslog或/var/log/messages)则能提供更广泛的线索。 - 如何创造日志:如果某个服务没有默认记录日志,可以通过修改配置文件开启日志功能,或者在代码中插入调试输出。对于某些难以复现的问题,甚至可以考虑使用专门的监控工具来捕获实时数据。
- 详细日志的重要性:在排查复杂问题时,基础日志可能不足以揭示问题的根本原因。此时需要开启更高日志级别(如 DEBUG 模式),以获取更详细的运行信息。
第二:按关联性排查
当问题出现时,可以根据组件之间的关联性逐步排查。这种思路的核心是从最直接的层面开始,然后逐步扩展到其他相关领域。
- 软件问题:如果某个软件运行异常,首先检查该软件本身的配置和依赖是否正确。例如,Nginx 配置文件是否有语法错误?依赖库是否缺失?版本是否兼容?
- 操作系统问题:如果软件层面没有发现问题,则需要考虑操作系统的影响。例如,权限设置是否正确?内核参数是否限制了某些功能?是否存在与特定版本相关的 bug?
- 硬件问题:如果排除了软件和操作系统的问题,就需要进一步检查硬件。例如,内存是否损坏?硬盘是否有坏道?BIOS 设置是否合理?
此外,有些问题可能涉及多个层面。例如,启动不了服务器既可能是系统问题(如引导文件损坏),也可能是硬件问题(如电源故障)。在这种情况下,需要综合分析日志和其他线索。
第三:通过问题影响排查
观察问题的表现形式,尤其是它对资源的消耗情况,可以帮助快速定位问题根源。
- CPU 和内存占用过高:如果某个服务进程大量使用 CPU 和内存,可能与系统内核参数或内存分配策略有关。例如,Linux 的
vm.swappiness参数会影响交换分区的使用频率,从而间接影响性能。 - 网络流量异常:如果某个服务进程产生了大量的网络流量,需要进一步分析其通信行为。例如:
- 它使用了什么协议?是 HTTP 还是HTTPS,是 TCP还是UDP?
- 它连接到了哪些地址?是否有可能存在恶意攻击或误配置?
- 网络带宽是否被耗尽?如果是,可以通过流量监控工具(如
iftop等)确认瓶颈。
通过这种方式,可以从问题的“症状”反推其根本原因。
第四:通过时间节点排查
时间是一个重要的维度,尤其是在问题突然出现的情况下。明确问题发生的时间点及其前后的变化,往往能迅速缩小排查范围。
- 自己的操作:回想最近是否进行了某些操作,例如更新软件、修改配置文件、添加新硬件等。例如,通过系统的包管理器(如
apt或yum)批量更新软件时,某个软件可能因为版本不兼容而出现问题。 - 他人的操作:如果服务器由多人维护,需要确认其他人是否进行了某些更改。例如,有人可能无意间修改了防火墙规则,导致网络连通性问题。
- 环境变化:除了人为操作,还需要关注外部环境的变化。例如,网络运营商是否调整了网络?数据中心的电力供应是否稳定?服务商的物理机是否发生变化?
通过对比问题发生前后的状态,可以更容易锁定问题的来源。例如,使用 diff 查看文件的变化,或者通过 history 命令查看最近执行的命令。
总之,以上四种思路——从日志入手、按关联性排查、通过问题影响分析、基于时间节点回溯——是我在解决服务器问题时常用的方法。每种方法都有其适用场景,具体选择取决于问题的性质和复杂程度。
当然要杜绝这些问题的出现,还是要多备份系统,多备份数据库。












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
评论