告别数据孤岛:如何通过数仓构建可信的“数据真相”?
数据仓库是面向主题、集成、持久、随时间变化的数据集,核心目标是打破企业数据孤岛,构建数据的真相,为经营决策、数据分析、业务运营提供可信的数据支撑。以下是我理解的落地方案 一、前期准备:需求调研与顶层规划 这一步是避免“技术自嗨”的关键,数仓建设必须以业务价值为核心,而非单纯的技术堆叠。 核心目标 对齐业务需求,明确建设边界、核心目标与实施路线,确保数仓落地后 [...]
数据仓库是面向主题、集成、持久、随时间变化的数据集,核心目标是打破企业数据孤岛,构建数据的真相,为经营决策、数据分析、业务运营提供可信的数据支撑。以下是我理解的落地方案 一、前期准备:需求调研与顶层规划 这一步是避免“技术自嗨”的关键,数仓建设必须以业务价值为核心,而非单纯的技术堆叠。 核心目标 对齐业务需求,明确建设边界、核心目标与实施路线,确保数仓落地后 [...]
基于前程无忧职位数据,全国共有3万多条数据,爬取了其中1.2万条数据。根据每个职位的数据做统计分析,以此来看Python职位具体的情况,而非单看某些文章吹学Python可以如何如何。 [...]
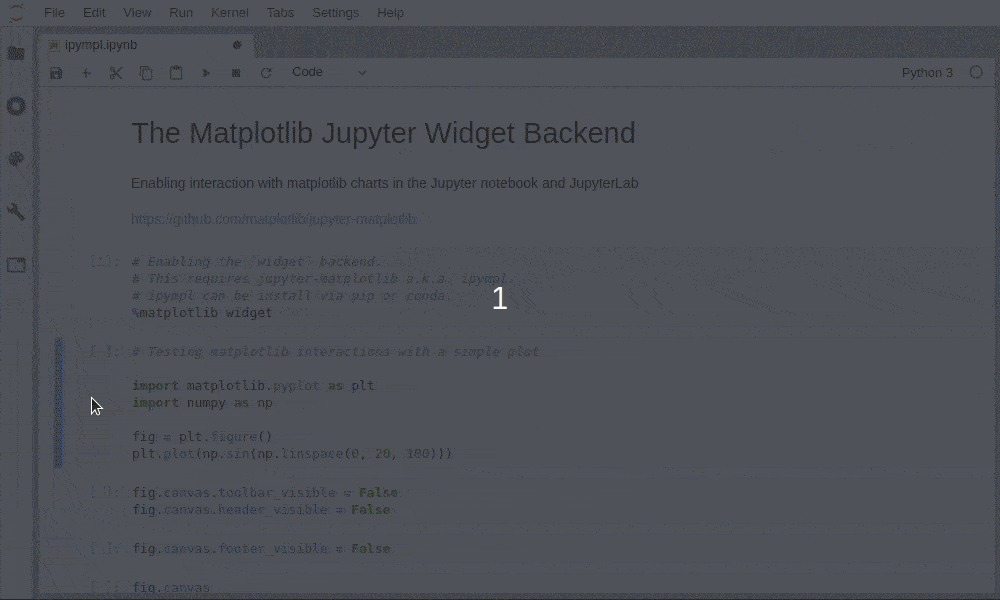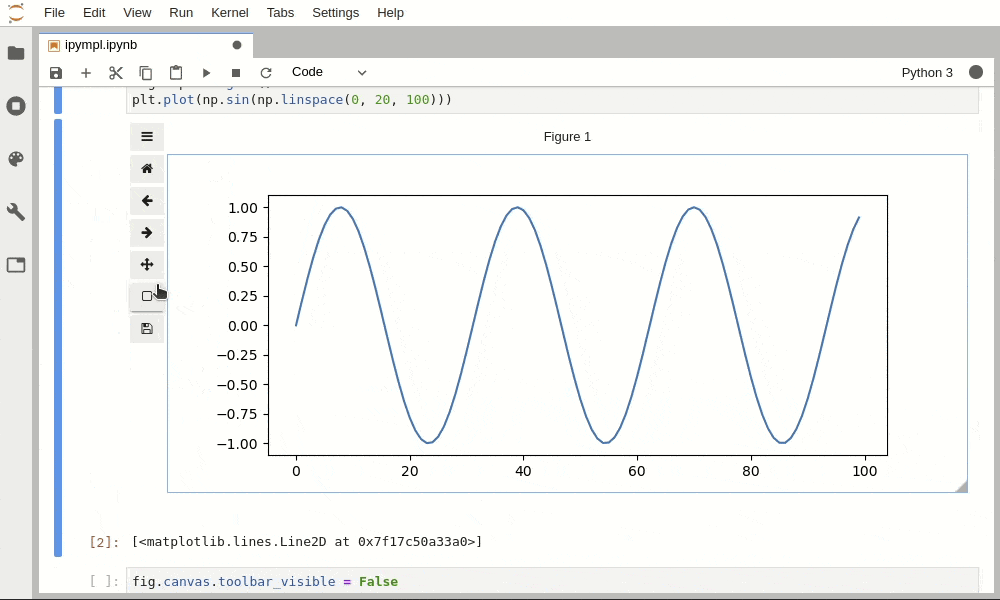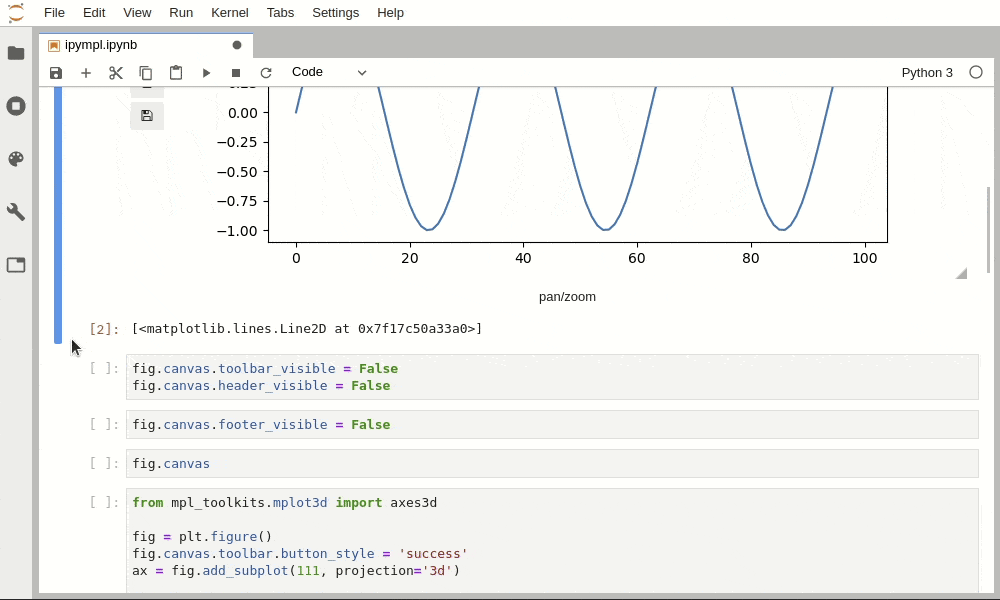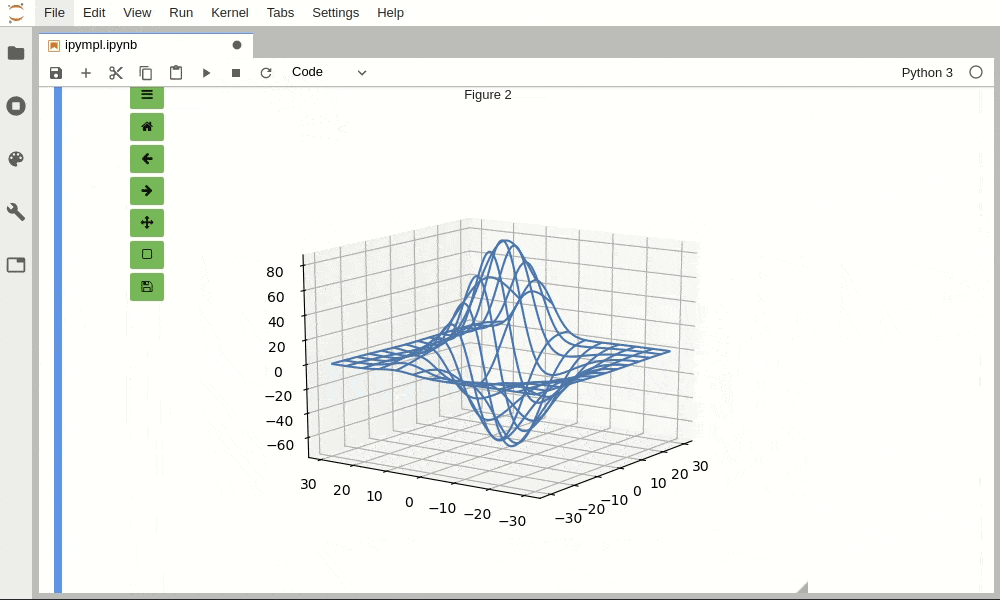
在Python安装了了matplotlib, plotly都可以比较方便绘制静态的图片,静态图片以特殊的字符串,保存在ipynb文件里面,而绘制动态图片需要安装插件。bokeh, pyecharts本身就是利用Javascript技术绘制动态的图片,而在JupyterLab里要加载使用的JS,也需要安装插件,或用一些方式来加载。 1.Matplotlib插件 [...]
这个数据科学项目由个人完成,注释比较完善,有目录与结论。涉及时间序列的处理,但有完善的地方,在结尾会补充。 总结 1.特征工程部分: 做这次考核作业用了4.5天时间,2天半的时间都在反复处理特征工程当中,1天半用来对比训练模型和做最后预测要提交的数据。 这次训练数据约25万多条,比较完好,821个店铺,分布在9个大区,103个城市当中。从不同店的客流图看 [...]
这个数据科学项目由个人完成,注释比较完善,有目录与结论,最后被老师评为机器学习章节考核的参考。 结论: 从连续型数据集来看,随机森林算法经过参数调整,测试集的准确度从85.95提升到了86.22,有一些效果,而AUC面积从0.9123提升到了0.9134,仅仅微微地提升。 从连续型数据集来看,梯度提升算法经过参数调整,测试集的准确度从86.57提升到了8 [...]