




![]()
Anaconda是Python其中一款集成环境管理软件,它包括了许多用于科学计算、数据分析和机器学习的Python第三方包。同样,也可以用它来构建Python的虚拟运行环境。
自己使用Python也差不
Python可用于不同的开发、编程任务,而不同的任务需要不同的环境,例如做WEB开发用的环境,就不要跟数据分析和机器学习的混在一起。当然,一开始所有包都安装到同一个环境也是可以的,但随着安装的包越来越多,包与包的冲突就会出现,导致运行网站、或数据分析的包不能运行。
Anconda会每半年出一个大的发行版本,安装之后有一个名叫Base的基础环境,里面的包的版本都是特定配好的,它们不一定都是最新的,但每个包都是互相兼容的。用conda安装包的时候,它会将兼容依赖包一同安装,并检查原来环境相关包的兼容性,从而尽可能让环境的兼容性最大化:用pip安装只检查是否有依赖,版本是否达到要求,而没有去检查与原来环境相关包的兼容性。现在新版pip(2020年8月30日开始发现的)也有一个选项--use-feature <feature>来开启。所以,用conda安装包的安装同一个包的时间(不算下载时间),要比pip安装的时间长。
有些重要的包之间要与相应的版本对应,而且要以自己实例运行代码为准。例如,在深度学习入门时,用的是tensorflow-gpu 1.14版本,网上很多教程说TF1.14版本要与Keras2.2.5版本,结果model.add(Embedding(len(vocab), EMBED_DIM, mask_zero=True))无法执行,去掉补0的参数项就可以,但这样训练模型的准确率很差,连30%都不到。后来才用 Stack overflow里找到解决方法,就是把Keras换回2.2.4版本即可。
目前自己的Base环境安装各种类型的包,所以依赖的包也不断更新上去,很难有100%的兼容性,但因为不专门用来跑特定项目,所以要让包丰富多样,什么东西都能运行。跑专门的项目、特定网站,还有机器学习和深度学习的要分别建立不同的环境,这样会好。由于,Anaconda放了不同的环境与包,也存了很多包的缓存,现在文件夹,从安装时7个G的,膨胀到45.6G了。所以要学数据分析、机器学习、深度学习这条线的同学,要在固态硬盘准备好一个100G以上的分区放各种运行环境。
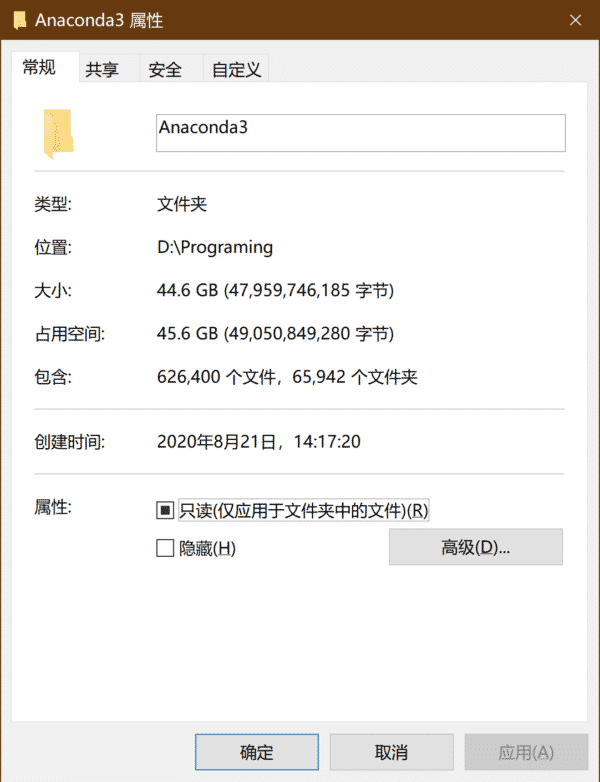
有些环境要保留一个软件的旧版本的包,而且安装相关包时也最好指定版本安装,因为代码也是基于不同版本的包写的。2020年Anaconda基础环境配的是scikit-learn 0.22版本。我学机器学习时,运行一些代码发现有些问题。于是新建环境装0.19版本,然后把最新的numpy, pandas, matplotlib, seaborn装上去时,发现还是有同样的问题。因为虽然sklearn指定了版本,但后面的numpy, pandas没有指定版本,于是sklearn的关键依赖包numpy版本也长到了1.19了。这样sklearn的PolynomialFeatures()无法将次数设置为0,也是因为numpy版本太新的问题。只要将numpy降到1.15以下版本即可。其实,用conda安装sklearn 0.19版本时,就会配上相关的numpy 1.14(具体情况有差异),不会装1.19版本。所以用conda安装某个包时,要看它也安装了哪些相关的包,它安装的是兼容的,自己没有必要重新安装,因为自己如果不指定版本安装某个包,很容易就包装到新的,导致不兼容的问题。














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
评论