




Window的图形界面,在使用数据分析绘制各种图片,并呈现结果的情况还是比较方便的。但是,代码是比在Linux的问题多一些,最常见的问题就是编码问题,中文Windows环境很多文本是用GBK编码,而在Python最好使用utf-8作为统一编码。
如果使用Windows10系统,网上有教程说可以通过“控制面板”,打开“区域”设置,找到“管理”选项卡,按“更改系统区域设置”,勾选“Beta 版:使用 Unicode UTF-8 提供全球语言支持”。按这种方式解决中文Windows系统的编码问题。
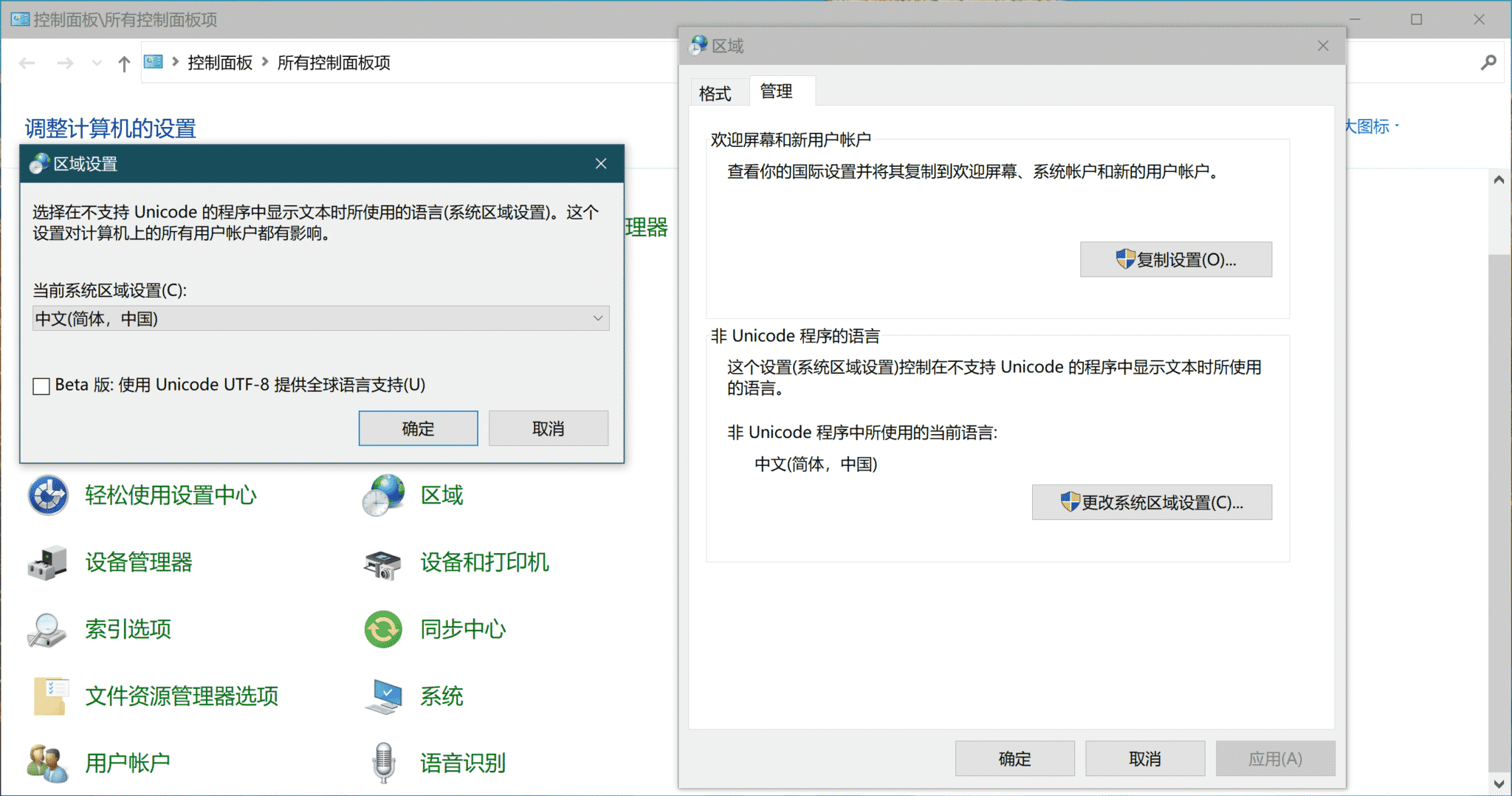
但打开这个之后,会令到其它的中文软件出现编码,或者其它奇怪的问题,例如Mindmanager编辑的导图,一但出现意外关闭程序就无法打开原来的文件,有时也不能正常保存,同样的字符可能要现输入一次才能保存。如果你的Windows还跑着一些老软件,还是不建议使用这种方法来解决编码问题。
现在Python在Windows系统的兼容程度很高了,如果出现编码问题:不能读写、读写出来是乱码,通过经验总结,它通常发生在读写各种文件时会出现,所以在这两个环节注意编码问题就可以了。解决的方法也很简单,在读写这些文件时加入encoding='utf-8'这个参数就可以了。
例如读写txt文件:
# 用简体中文编码读取
with open('filename.txt', encoding='gbk') as f:
pass
# 以UTF-8保存
f.write('filename.txt', encoding='utf-8')
例如用Pandas读写CSV文件:
# 用德文的编码打开文件
df=pd.read_csv('train.csv', encoding='ISO-8859-1')
# 用UTF-8保存
df.to_csv('finish.csv', encoding='utf-8', index=False)
总之,在用Python处理各数据流程的文件时,一定要将其调整并统一为UTF-8。














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
评论