




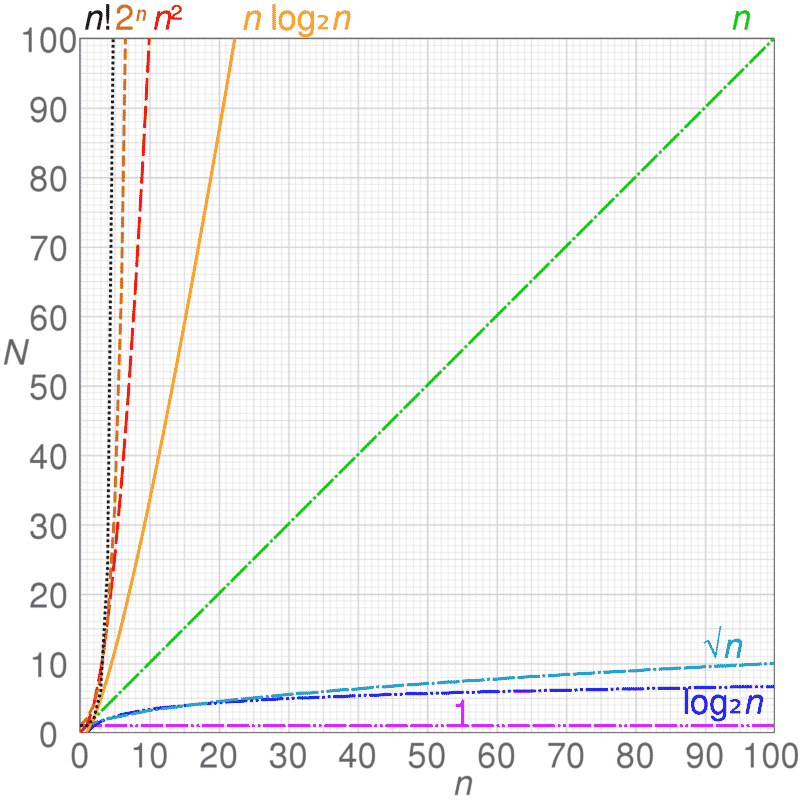
complexity
最近写了一个随机数据生成的程序,下文简称生成器。使用的逻辑也很简单,就是用random包生成数字、字符串的组合,赋值到变量,然后按原来JSON文件的结构组装在一起,形成一个JSON记录。这个过程是没有用到任何循环语句。
之后,就是根据测试的要求将不同比例和特定特征的记录组合到一起,放到Kafka服务器。其中随机数据的生成器用时相对最慢,因为多了一个变量是三个随机值组成,混合数据是在中间(有随机和顺序数据),最快是顺序数据,它是少了一个随机变量并将另一个变量改成顺序的值。
我原以为没有嵌套循环应该不会出现时间复杂是O(n^2)的情况,结果在开发机生成1万只有160秒左右,到10万就要16000秒,远超我的估计。我开始分析是不是在生成随机变量之后的修改,增加了复杂度,结果没有。然后把混合数据生成器要跑的两次循环,改成一次循环两步来解决,发现生成混合数据的用时可以减少10%左右。最后,就把要生成的数据分批来生成写入,因为我发现数据量的增长与时间的增长成平方关系,所以每次生成小批量的数据应该可以保持时间复杂度在较低的维度,也是接近O(n)。
然后,经过不同批量的测试,从100每批到500每批,生成20万以下的数据,每次生成同一批量的不同总量数据之间,呈倍量关系。因为每批量生成的基准时间不同,发现在500-1000每批生成100万数据的时间大概在2100秒左右,比之前生成10万数据要少,相当于之前算法生成3.6万的时间。
一开始写的时候,就考虑过时间复杂度的问题,就想过用多线程或多进程的方法,但用的是python 2.7版本,加上对数据顺序的修改,这种情况比较难确定,所以没有用。在服务器开发机的时间比在自己的开发机的生成时间要慢2倍。比较了自己的开发机和服务器开发机的CPU,服务器的频率更高,代数会落后一点,CPU不应该是瓶颈。也比较了写入在机械和固态硬盘的速度,也没有多大差异。所以,最后想到瓶颈应该是在内存的频率上,还有也因为CPU代数有差距,CPU一级二级缓存可能会少一点,当然这点差异不还是很确定。
所以,大批量数据生成的性能瓶颈应该在内存IO频率上。














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
评论